

How to Streamline Data & Pagination in ADF Pipelines

Efficient extraction of data from diverse sources has become a cornerstone of successful ETL workflow. Within this paradigm, Azure Data Factory emerges as a robust platform, empowering businesses to direct complex data pipelines seamlessly. However, when grappling with large datasets sourced from REST APIs, the necessity for accurate management becomes apparent. This necessity brings us to the forefront of an essential aspect of data extraction: pagination.
The process of pagination, which divides data retrieval into manageable chunks, is of the utmost significance for enhancing ETL operations, especially in the context of the ADF ecosystem. It is an essential tool for optimizing data extraction, guaranteeing scalability, and preserving system effectiveness. Organizations may maximize the value of their data assets and lessen the difficulties presented by large data streams by handling the complexities of pagination within Azure Data Factory ETL pipelines.
In this post, we'll see the intersection of Azure Data Factory, REST APIs, and pagination, paving the way for streamlined and efficient data extraction processes.
Let's get started!
Table of Contents
- Understanding Azure Data Factory and ETL
- Commonly Used Terms in ADF
- Performing Copy Activity in Azure Data Factory
- Pagination in Azure Data Factory
- Customized Solutions for the POST Endpoint
- Best Practices for Optimizing Pagination in ADF
- Conclusion
- Frequently Asked Questions
Understanding Azure Data Factory and ETL
ADF serves as a pivotal component in modern data management strategies, offering a comprehensive platform to seamlessly integrate disparate data sources, streamline data movement, and facilitate transformation before loading data into designated destinations. It simplifies the extraction phase by providing a unified interface and a wide array of built-in connectors to various data repositories, including cloud-based services like Azure Blob Storage and on-premises databases based on your requirements. This facilitates the retrieval of data from a particular source with consistency and reliability.
ADF empowers users with robust transformation capabilities, allowing them to cleanse, enrich, and shape data according to their specific requirements. Its intuitive visual interface and extensible scripting options enable the implementation of complex transformation logic, ensuring that data is prepared for downstream analytics or reporting processes efficiently.
Do You Know?
Big players such as Infosys, eBay, Panasonic, Fujitsu, and HTS Inc. Consultants are among the notable companies utilizing ADF.
In the loading phase, ADF excels in integrating with Azure's ecosystem of data storage and processing services, ensuring efficient and reliable data transfer into target destinations. This simplifies the process of loading transformed data to derive maximum value from their data assets while reducing complexity and operational overhead.
Take a glance at some commonly used terms in ADF and their meanings:
Linked Services
Linked Services serve as connection configurations that define the connection information needed for data movement and data processing activities. They establish connections to external data sources and destinations, such as databases, data lakes, and cloud services. Linked Services store connection strings, authentication details, and other relevant information required to interact with these data stores. By configuring Linked Services within ADF, you can seamlessly integrate with various data sources and destinations, enabling efficient data movement and transformation across diverse environments.
Dataset
Datasets identify data within different data stores, such as tables, files, folders, and documents. Before you create a dataset, you must create a linked service to link your data store to the service. Linked services are much like connection strings, which define the connection information needed for the service to connect to external resources. By defining datasets within ADF, users can standardize data access, streamline data processing workflows, and facilitate data movement between various stages of the data pipeline.
Pipelines
Pipelines in ADF serve as containers for managing data workflows, encompassing a sequence of interconnected activities that perform data movement, transformation, and processing tasks. Pipelines provide a visual representation of the end-to-end data flow within ADF, allowing users to define the sequence of activities, dependencies, and execution logic. This enables automating complex data integration and transformation processes, facilitating the efficient movement of data from source to destination and monitoring capabilities.
Activities
Activities represent individual processing steps or tasks within pipelines that perform specific data movement, transformation, or control flow operations. They encapsulate actions such as copying data, executing stored procedures, running custom scripts, and performing data transformations. Activities can be categorized into various types, including data movement activities, data transformation activities, control flow activities, and custom activities.
Trigger
Triggers enable the automatic execution of pipelines based on predefined schedules, events, or external triggers. They provide the mechanism for initiating data integration and processing workflows in response to specified conditions or events, such as time-based schedules, data arrival, or external signals from other Azure services. Triggers can be configured to execute pipelines at regular intervals or on-demand, providing flexibility and automation in managing data workflows within ADF. They facilitate the timely and efficient execution of data integration processes, ensuring that data pipelines are triggered and executed as needed to meet business requirements.
Hey there! Before you continue, why not take a quick look at the diagram below? It's a visual guide showing the connections between pipelines, activities, datasets, and linked services. It might just give you some valuable insights!
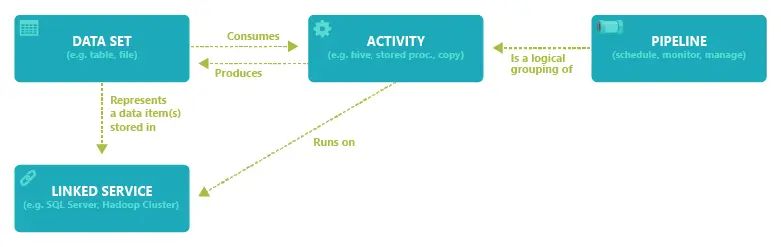
Performing Copy Activity in Azure Data Factory
Create source dataset
- Begin by navigating to the Azure Data Factory interface and click on "Datasets" to create a new dataset representing the source data you intend to copy.
- Choose the appropriate connector for your source data store based on your requirements.
- Configure the dataset properties including name, structure, format, and connection settings according to the specifications of your source data.
Have a look at the screenshot for creating REST dataset and configuring linked services to ensure seamless integration with external resources:


Created sink dataset
- Similarly, proceed to create a new dataset to represent the destination (sink) where you want to copy the data.
- Select the relevant connector corresponding to your sink data store, ensuring compatibility with the source dataset.
- Configure the sink dataset properties including name, structure, format, and connection settings to match the requirements of your destination data store.
The below mentioned screenshot shows how to sink data set that will sink data from REST dataset to a SQL server for efficient data integration and storage.

Mapp source response with sink data set objects
- After creating the source and sink datasets, proceed to map the response from the source dataset to the objects in the sink dataset.
- In the ADF interface, navigate to the "Mappings" section within the pipeline canvas or copy activity settings.
- Define mappings between the fields or columns of the source dataset and the corresponding fields or columns in the sink dataset.
- Ensure that the mapping accurately reflects how data should be transformed and loaded into the destination, considering any differences in schema or data structure between the source and sink datasets.
- Review and validate the mappings to ensure correctness and consistency, adjusting as necessary to achieve the desired data transformation and loading process.

Pagination in Azure Data Factory
Standard Approaches
Query Parameter and AbsoluteURL are the standard approaches used for defining datasets and interacting with REST APIs to ingest or retrieve data from various sources.
Query Parameter
This approach is commonly used when the REST API requires parameters to be passed within the URL itself to specify the data to be retrieved. Query parameters are appended to the base URL to filter or specify the data to be retrieved from the REST API.
- In this approach, the dataset definition includes a base URL along with query parameters.
- If you're fetching data from a REST API endpoint that requires filtering based on certain criteria, you would include those criteria as query parameters in the dataset definition.
For instance, let's say we're sending multiple requests with variables stored in QueryParameters:
- Enter "sysparm_offset={offset}" either in the Base URL or Relative URL, as illustrated in the screenshots below:
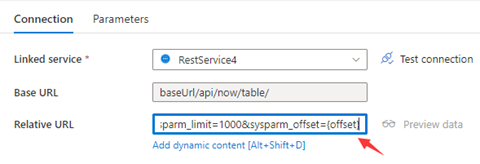
Source: Copy and transform data from and to a REST endpoint by using Azure Data Factory
- Now, set Pagination rules as:
"QueryParameters.{offset}" : "RANGE:0:10000:1000"
Absolute URL
This approach is suitable when the REST API endpoint provides direct access to the required data without the need for additional parameters.
- Unlike the Query Parameter approach, all necessary parameters and criteria are included directly in the URL itself.
- In the Absolute URL approach, the dataset definition consists of a complete URL pointing directly to the specific resource or endpoint from which data is to be fetched.
Take an example where we're sending multiple requests with variables stored in Absolute URL:
- Insert {id} either in the Base URL on the linked service configuration page or in the Relative URL in the dataset connection pane.
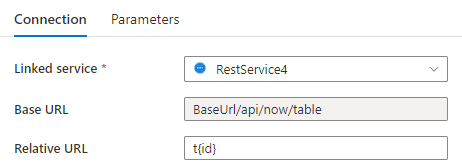
Source Copy and transform data from and to a REST endpoint by using Azure Data Factory
- Set Pagination rules as:
"AbsoluteUrl.{id}" :"RANGE:1:100:1".
Headers
Headers provide essential details for servers to process requests efficiently.
- Note that the specific headers required may vary depending on the API endpoint being accessed and the requirements set by the server.
- They specify data format (e.g., JSON), API version, and authentication via keys.
Let's take an example where we're sending multiple requests with variables stored in Headers:
- Add {id} in additional headers and set pagination rules as "Headers.{id}" : "RARNGE:0:100:10".
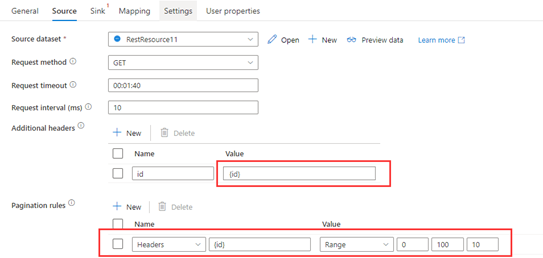
Source Copy and transform data from and to a REST endpoint by using Azure Data Factory
Customized Solutions for the POST Endpoint (Accepts Pagination inside its Request Body)
Our approach to customized solutions for POST Endpoint implementation centers on leveraging Azure Data Factory's versatile capabilities. We navigate through each step from declaring variable to configuring Execute Pipeline activities tailored to your specific needs. By seamlessly integrating iterative web connections to ensure efficient data transfer and processing.
Step 1: Declare Variable
Define the necessary variables which might include parameters such as page numbers, endpoint URLs, or any other data needed for the operation.
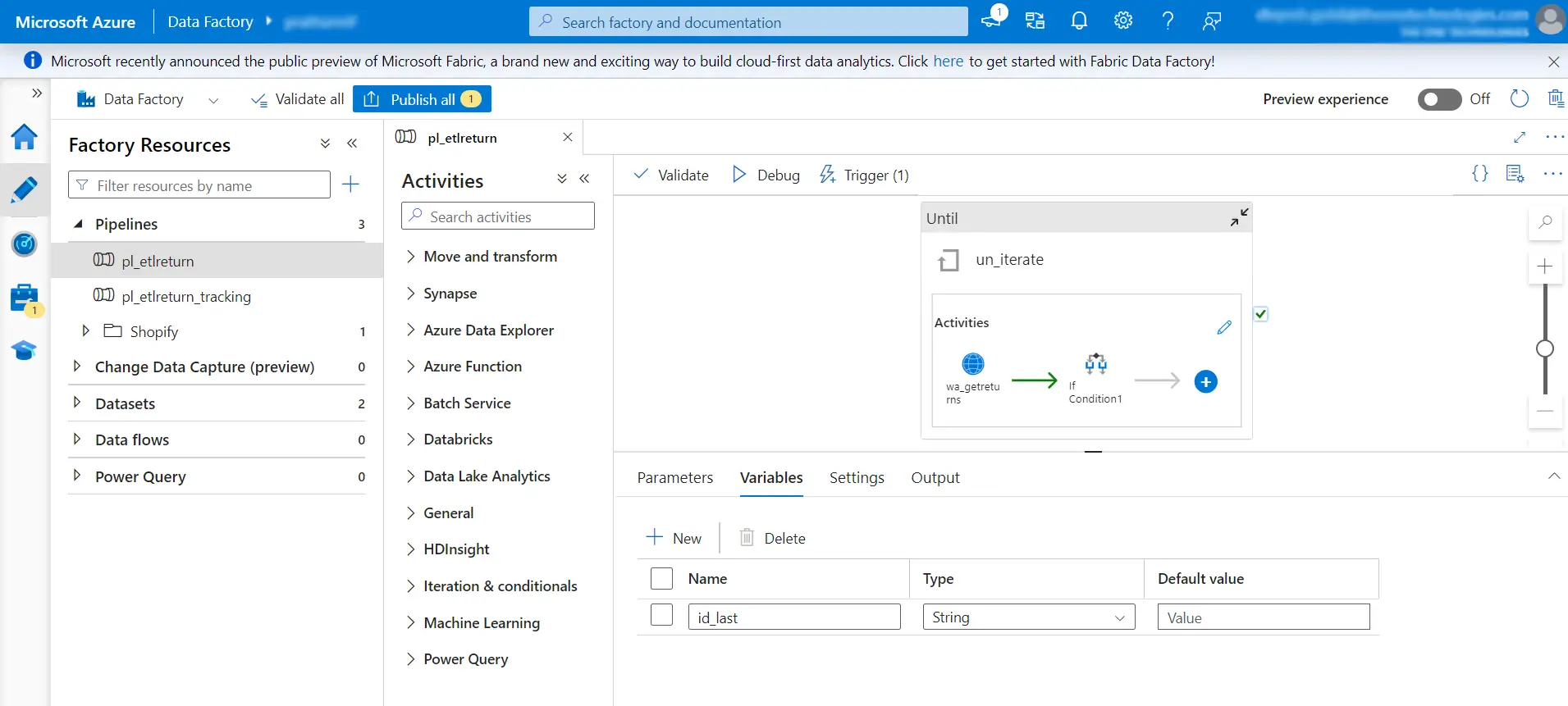
Step 2: Create an Until Activity that Iterate on Each Page
Set up an "Until" activity to iterate through each page until a specific condition is met. This condition could involve reaching the last page of a dataset or fulfilling a certain criterion.

// Expression: Expression that must evaluate to true or false
// Timeout: The do-until loop times out after the specified time here.
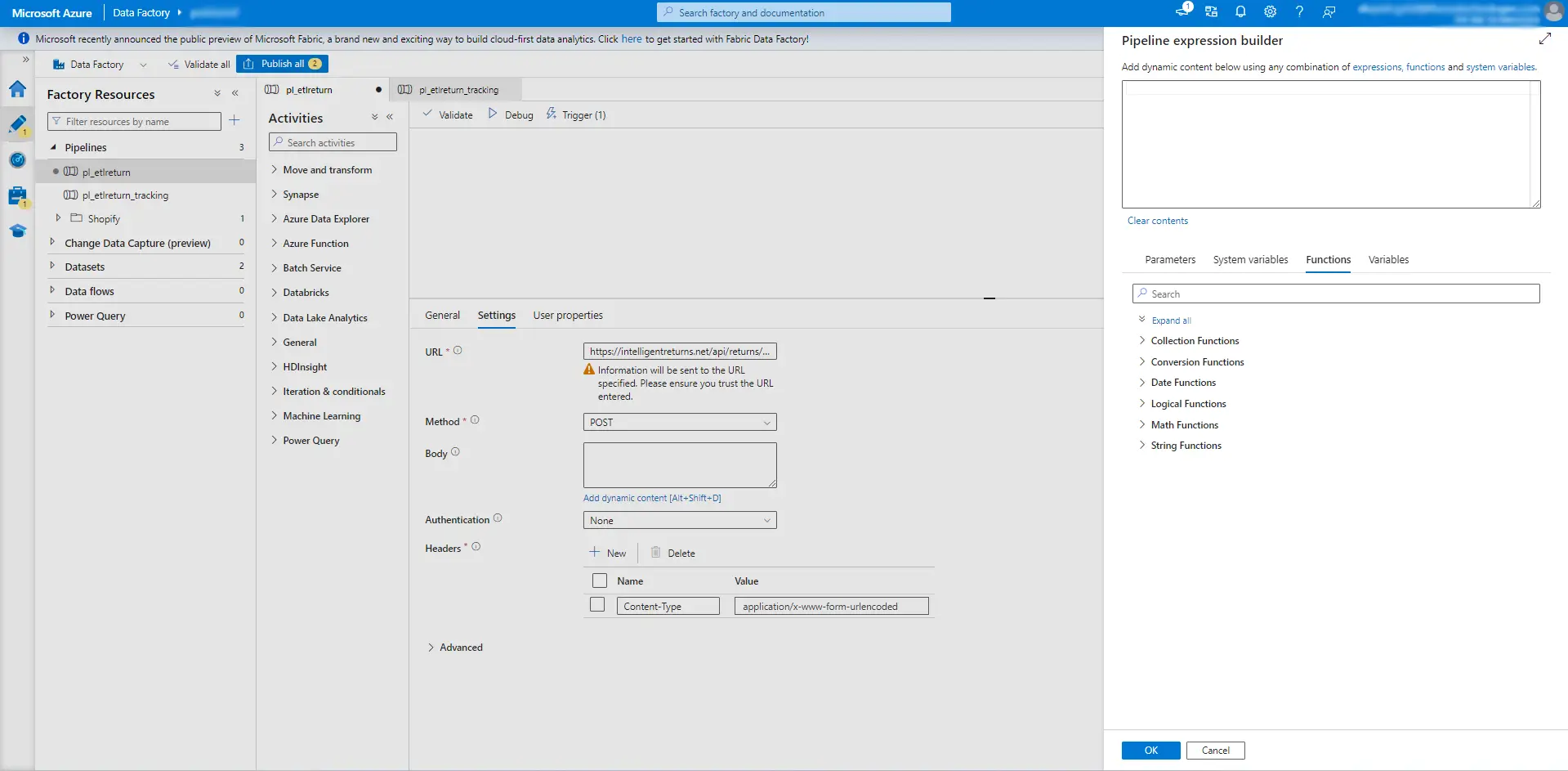
Step 3: Create Web Activity and Call a Desired POST Endpoint
Implement a web activity within the loop to interact with an external system. This activity should be configured to make a POST request to the desired endpoint, providing any necessary data or parameters.
Step 4: Configure a Set Variable Activity
Utilize a "Set Variable" activity to update variables as needed during the execution. This step might involve storing response data from the web activity or modifying iteration counters.
Step 5: Create a Child Pipeline and Define Parameters in it
Create a child pipeline that encapsulates a specific set of actions. Define parameters within the same pipeline as it will be used to customize its behavior or to receive input from the parent pipeline.
Step 6: Configure Execute Pipeline and Invoke Newly Created Pipeline with Parameter Passing
Configure Execute pipeline of the parent to invoke the newly created child pipeline. Make sure that parameters required by the child pipeline are passed from the parent pipeline, allowing for customization between the two processes.
Note: The Until activity will iterate through all the above-mentioned steps till expression given in Until activity is satisfied.
Additional:
You can also use default functions such as:
- Collection functions
- Conversion functions
- Date functions
- Logical functions
- Math functions
- String functions
Best Practices for Optimizing Pagination in ADF
Efficient API Endpoint Selection
Choosing API endpoints that allow effective pagination methods is essential when constructing ADF pipelines for pagination. To manage the quantity of data fetched for each request, look for endpoints that provide options like page size and offset. Select endpoints that offer the best performance and correspond with your data retrieval requirements to minimize superfluous overhead.
Dynamic Pagination Parameter Handling
Use ADF pipelines with dynamic pagination parameter handling to adjust to changing data volumes and maximize resource use. To dynamically determine pagination parameters, such as page size, offset, or token values based on runtime conditions, use pipeline expressions or parameters. With this method, pagination management across many datasets and contexts is guaranteed to be flexible and scalable.
Incremental Loading
Instead of retrieving the complete dataset in each pagination request, use incremental loading techniques to fetch only the necessary data sequentially. Use techniques like incremental key-based filtering or timestamp-based filtering to get newly added or changed records since the previous pagination iteration. This increases overall performance and efficiency by reducing the burden on the ADF resources as well as the source system.
Parallel Execution
Utilize ADF pipelines' parallel execution features to increase throughput and decrease pagination processing time. Divide pagination requests into several concurrent threads or activities to retrieve data from various pages or endpoints at the same time. This method can speed up data retrieval and make use of the available resources, especially for big datasets or high-volume APIs.
Error Handling and Retry Logic
Use retry logic and strong error handling to deal with temporary disruptions or failures that could happen during pagination queries. Set up retry policies with exponential backoff methods at the activity or pipeline level to automatically retry pagination requests that fail. Implement systems to record faults, gather diagnostic data, and escalate problems for additional research or fixing as well. By doing this, pagination errors are handled with resilience and dependability, and the influence of fleeting problems on pipeline execution is reduced.
Suggested Reading
Conclusion
Optimizing data extraction and pagination within Azure Data Factory ETL pipelines is paramount for efficiently managing large datasets sourced from REST APIs. By implementing dynamic pagination strategies, leveraging parallel execution, and employing error-handling mechanisms, organizations can streamline the process of retrieving data while minimizing resource usage and maximizing performance. Also, incorporating best practices such as incremental loading and efficient API endpoint selection ensures that data extraction workflows are scalable, reliable, and adaptable to evolving business needs.
Frequently Asked Questions
- How can I handle pagination dynamically in Azure Data Factory pipelines?
You can handle pagination dynamically by utilizing pipeline expressions or parameters to calculate pagination parameters such as page size and offset based on runtime conditions or input parameters.
- What are some best practices for optimizing pagination in Azure Data Factory?
Best practices include selecting efficient API endpoints, implementing dynamic pagination parameter handling, utilizing incremental loading, parallelizing execution, robust error handling, and retry logic.
- Why is pagination important in data extraction within Azure Data Factory ETL pipelines?
Pagination is crucial for efficiently retrieving large datasets from REST APIs in manageable chunks. It helps prevent overwhelming the system and ensures smooth data extraction while optimizing resource usage.
- How do you monitor and optimize the performance of data extraction and pagination pipelines in Azure Data Factory?
We utilize Azure Data Factory's monitoring and logging capabilities to track pipeline execution metrics, identify bottlenecks, and optimize performance. Through continuous monitoring and fine-tuning, we ensure that data extraction and pagination pipelines operate efficiently, delivering reliable and timely results for our clients.
- Can Azure Data Factory handle complex data transformation requirements during pagination?
Yes, Azure Data Factory provides robust transformation capabilities, allowing us to apply complex data transformation logic during pagination. We can seamlessly integrate data cleansing, enrichment, and schema mapping within our ETL pipelines to meet our specific business needs.






